
Foundation Models in Biology Need More Data
Large language models benefit from vast internet training datasets. Self-driving cars can collect enormous amounts of data simply by driving around. In biology, however, we face a bigger challenge: limited public datasets and costly experiments to generate new data.
Public datasets for training models in biology are scarce, and even when they are available, they are often incomplete. Protocol details are frequently missing or not fully documented, leaving out critical factors that influence experimental outcomes. Whether the media was pre-warmed, how quickly it was exchanged, how edge effects in plate layouts were handled, or the lineage and passage history of the cells, all of these variables that go unrecorded have the potential to shape results but are rarely described in publicly shared datasets.
Generating new biological data is expensive and requires deep domain knowledge, so narrowing the search space is critical. This means defining clear experimental boundaries, such as volume ranges, step sizes, and media components. It also means being selective about what data to collect. For instance, images need to provide enough signal to be useful without the burden of capturing every layer of a 100× Z-stack. Setting these boundaries depends on a blend of automation expertise and years of hands-on biological experience.
Finally, none of this is feasible without the right automation, software, and infrastructure. Efficient, high-quality experimentation depends as much on the tech infrastructure enabling it as on the biological insight behind it.
Level 4: Fully Autonomous Experimentation
In the previous post we covered levels 0 to 3 in cell culture automation. Level 4 represents the leap from automated to autonomous science. Here, the system doesn’t just help execute experiments, it decides what to try next. The loop between observation, reasoning, and action is fully automated and closed without a human in the loop.
At this stage, fully autonomous experimentation replaces the day to day human decision-making with an optimization algorithm. Instead of keeping humans in the loop for decisions about media feeding, passaging, termination, or downstream analysis selection, an optimization algorithm determines the next experiment. Human decision-making shifts to strategic oversight.
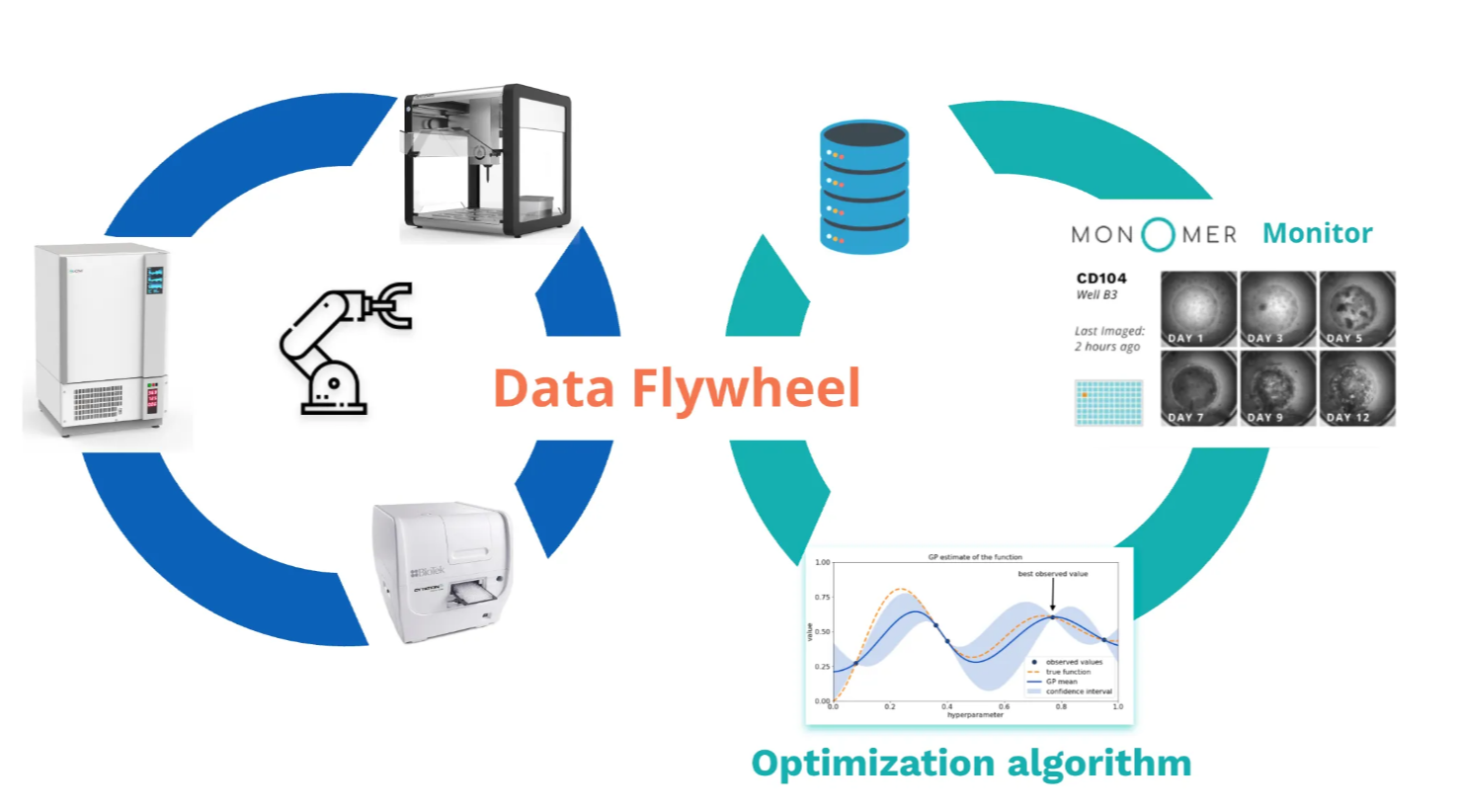
This approach has proven especially powerful for media optimization where thousands of possible media components and combinations can be explored far faster and more systematically than human intuition allows. With our customer Dragonase, we've developed a fully autonomous stem cell experimentation workflow. As described in our Case Studies page, the challenge was to efficiently search through a vast parameter space of growth factors, basal media, and supplements at different time points and dilutions. We iterated through this process by:
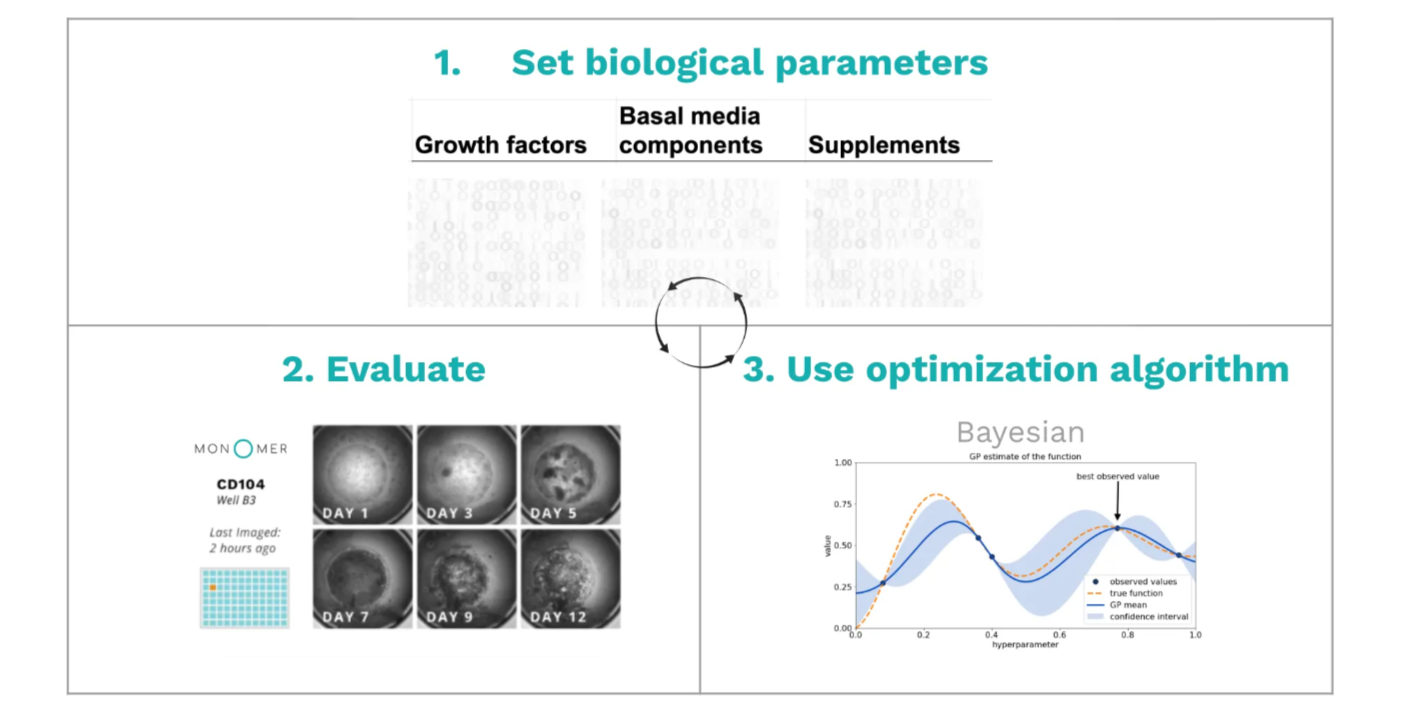
- Setting biological parameters like which growth factors, basal media components, or supplements to test and at what dilutions.
- Evaluating those parameters by executing experiments with the specified parameters, capturing data, and computing results.
- Using a Bayesian optimization algorithm to determine the next set of parameters to test.
This approach turns the lab into a search engine for biology which can explore vast parameter spaces faster and more systematically than any human team could. The true challenge of Level 4 isn’t in the math, it’s in applying the domain knowledge of wet lab biology. Having the tacit knowledge of what’s possible, what’s worthwhile to measure and what's not practical, and what’s expensive versus cheap to test requires years of accumulated experience. There are so many papers to read that no human can possibly read and see patterns across all papers and update their mental model with experiments in the lab. Level 5 promises to do just that.
Level 5: Super Intelligence
Level 5 is where AI experiments and uncover biology’s truths guided by real biological feedback. At this stage, the lab becomes a reinforcement learning environment for scientific discovery. Scientists shift from experiment executors to system designers, curating hypotheses, constraints, and biological priors.
Recent foundational models already show us the fruits of this promising approach. AlphaFold learned protein structures directly from data, ESM-2 generalized protein representations across prediction tasks, and GNoME discovered millions of new stable materials through exploration. These systems demonstrate how foundational models can generate novel predictions. But these predictions require empirical validation. Active learning must be supported by actual experiments, whether in an automated wet lab or through a simple request to a scientist to run an experiment.
At Monomer Bio, our automated platform functions as a reinforcement learning environment for training foundational models in biology. By integrating closed-loop laboratory automation with AI-driven decision-making, the platform allows models to use the wet lab as their learning environment:
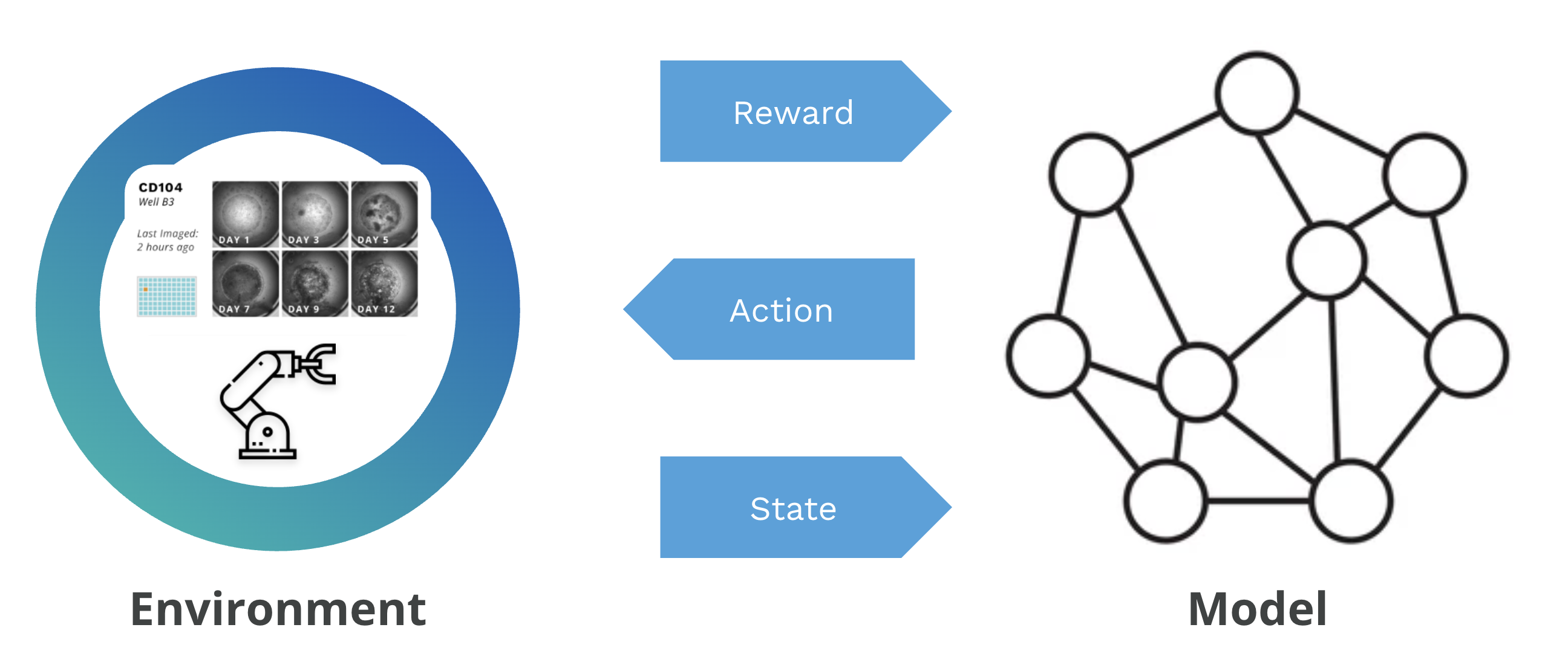
- Rewards: measuring success against experimental objectives (by comparing biomarkers and cell morphology).
- Actions: designing experiments (such as selecting growth factor combinations).
- State: interpreting biological outcomes (by examining resulting phenotypes).
This framework enables training models not just on static datasets but through active experimentation, where they can iteratively propose, test, and refine hypotheses. Each iteration improves the foundational model enabling agents to serve as scientific collaborators.
We believe the best learning environments are not manual CROs with sparsely documented processes but fully automated autonomous labs that comprehensively capture and structure data. When models can autonomously hypothesize, test, and refine, we’ll have reached a new frontier: not just more efficient science, but the ability to see patterns across literature that no single human can keep in their head while continuously updating the corpus of well anotated structured data available. That’s the essence of scientific super intelligence. A system that not only automates biology but expands the context with wich we understand biology.
Next
Our vision is to turn today’s manual artisanal cell culture into an industrialized engine for reliable data generation at scale. Whether you’re developing disease models, training biological foundation models, or manufacturing next-generation therapeutics, we’d love to work together to bring autonomy to your lab.
In our next post, I'll make a call for collaboration. In the first phase of our company we’ve helped biotech labs industrialize iPSC-derived in vitro disease models. Now, we’re looking to help AI companies build foundation models by providing a reinforcement learning environment to train, fine-tune, and validate their models (virtual cell, toxicity, etc) with real biology experiments. Lastly, we’re looking to partner with instrument makers to expand lab automation capabilities from microplate- to flask-based volumes, reduce instrument costs, and derisk sterility.
We’re entering a new era with a lot of interest in pointing AI at scientific experimentation. At Monomer Bio, we’re building the tech infrastructure that make that possible to explore the unknown universe of living cells. Let’s build the infrastructure for biology’s next leap forward together.
